Medusa
I remember when MedusaTogether2024 was published. That morning, a couple of colleagues’ computers at the office were open to the PDF (not that I spy on people’s screen). If this isn’t your case for every new Tri Dao paper, you have some soul-searching to do.
Medusa proposes to augment the language modeling head of any Transformer model with additional heads which predict future tokens, in parallel. This differs from traditional speculative decoding in that the speculator is not a separate model but rather an extension which leverages the original model’s hidden states. In addition, because predictions happen in parallel latency is greatly reduced.
A Medusa head is defined as layers of feed-forward and residual connections followed by a LM head. In practice, a single layer suffices.
from tinygrad import Tensor
# Hidden dimension, Vocab size, Heads.
H, V, N = 2048, 8192, 2
class Medusa:
def __init__(self, model):
self.model = model
# We batch the linear layers and heads.
self.w1 = Tensor.kaiming_uniform(N, H, H)
self.w2 = Tensor.kaiming_uniform(N, H, V)
def __call__(self, x, positions, cache, mask):
h, logits, cache = self.model(x, positions, cache, mask)
h = h.expand(N, -1, -1)
h = h + (h @ self.w1).silu()
medusa_logits = h @ self.w2
return logits, medusa_logits, cache
The above module produces logits for future tokens from which we can draw probability distributions. For each head , we select the highest probability tokens to evaluate.
model = Model()
medusa = Medusa(model)
# A dummy, single-token sequence
x = Tensor(tokenize("[BOS]"))
# Pass through the model, predict the next token.
logits, medusa_logits, cache = medusa(
x,
positions=Tensor([0]), # The [BOS] token has position zero.
cache=Cache(), # Empty, imaginary KV cache.
mask=Tensor([[0]]), # The [BOS] token can attend to itself.
)
choice = logits[-1].softmax().multinomial()
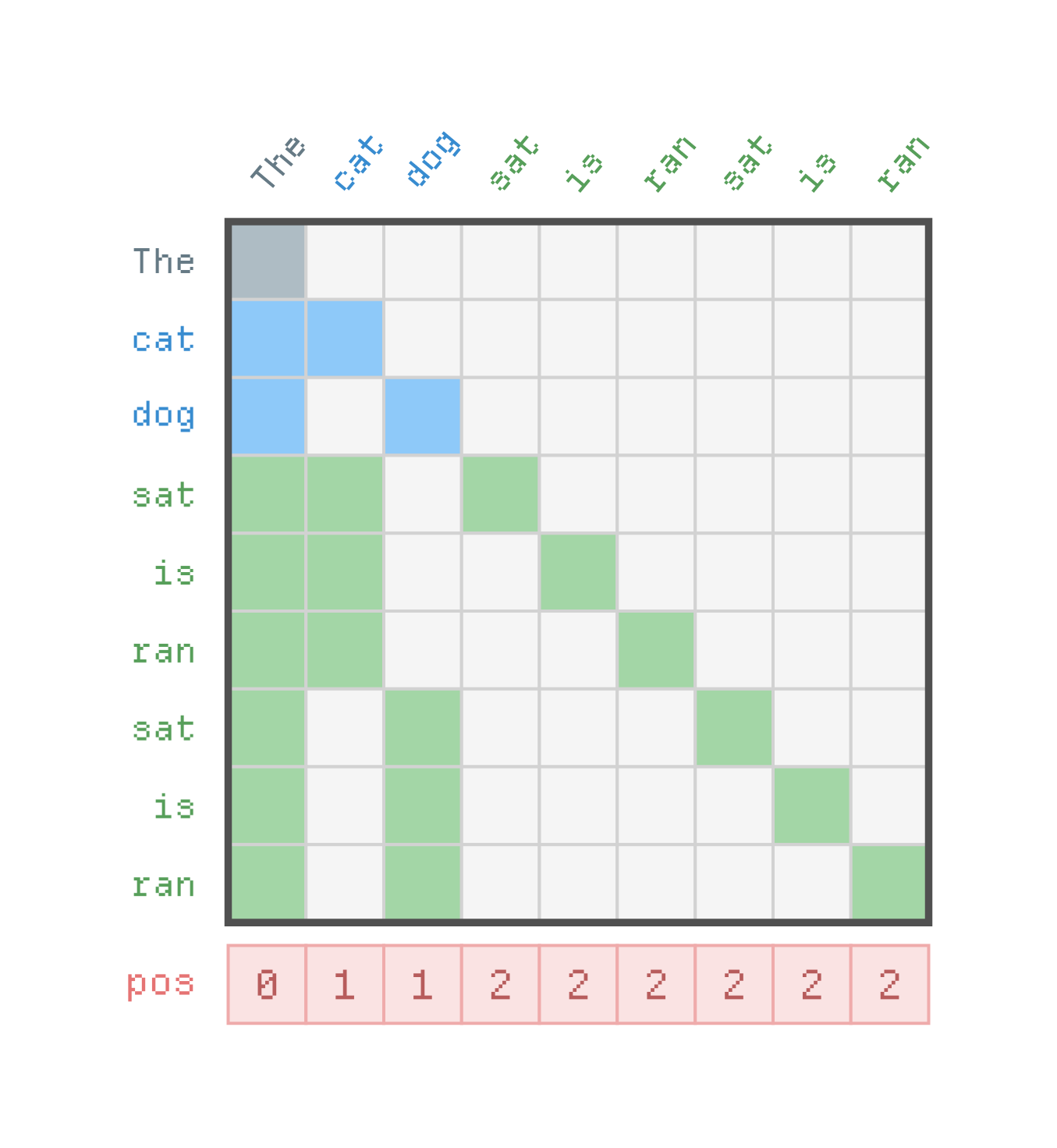
This gives us a tree of candidate sequences of length .
# We select the top-2 tokens from the first head, top-3 from second.
S = Tensor([2, 3])
# This leads to 2×3 possible sequences.
K = S.prod().item()
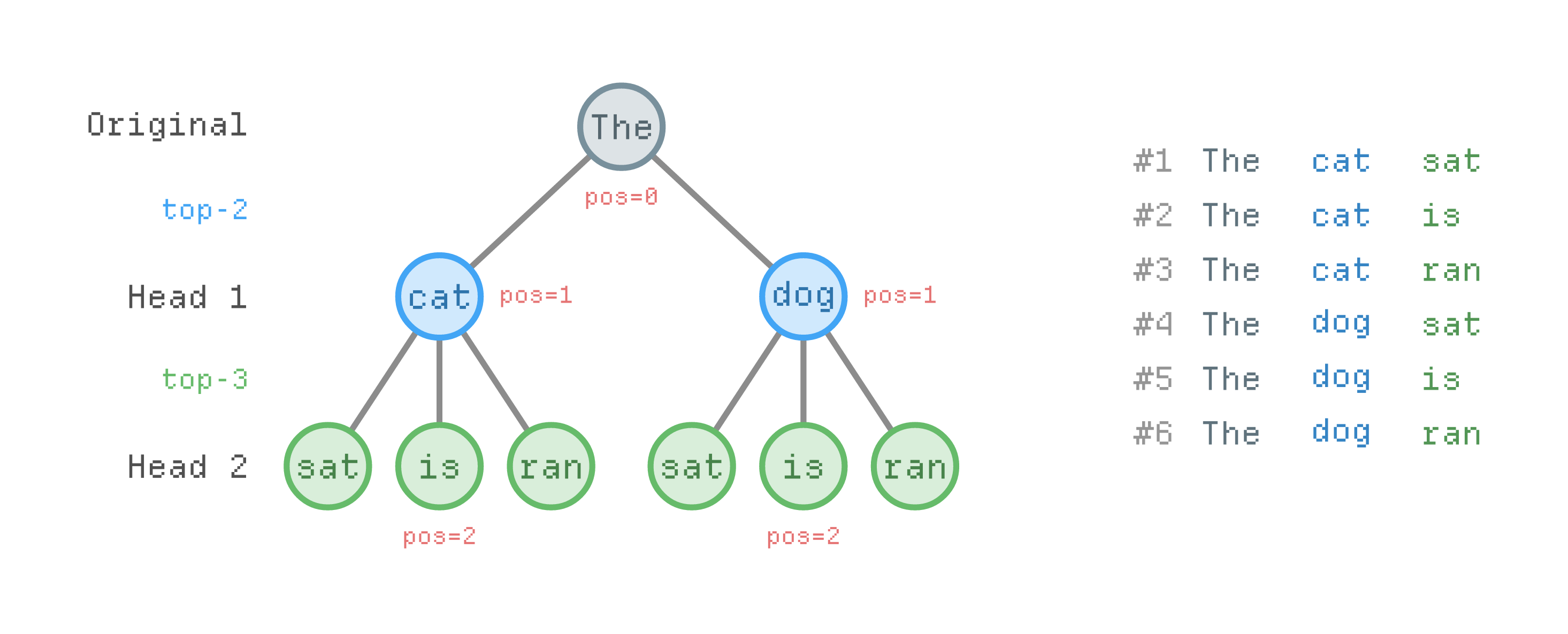
The next step is to score each branch using the target model. We construct an input of length which contains the model’s prediction and the flattened tree.
s = 1
x = Tensor([choice])
positions = Tensor([1])
for i in range(N):
_, ids = medusa_logits.topk(S[i])
x = x.cat(ids.repeat(s))
positions = positions.cat(1 + S[i] * s)
s = S[i]
Finally, we construct an attention mask which prevents tokens from different branches to attend to one another. Funny enough, this scenario heavily resembles paged attention with prefix matching from the world of LLM-inference.
{todo}