Introduction
Speculative decoding is a popular technique in autoregressive LLM inference that aims to reduce the number of forward passes of a target model using a draft model. It was introduced in Accelerating Large Language Model Decoding with Speculative SamplingDeepmind2023 and improved in many subsequent works. Coincidentally, other research teams published the idea around the same time as DeepMind.
The intuition behind speculative decoding is that not all predictions require a full pass through the model. When generating text, many tokens are obvious from context, and can be guessed by a smaller model faster and cheaper.
Speculative Decoding
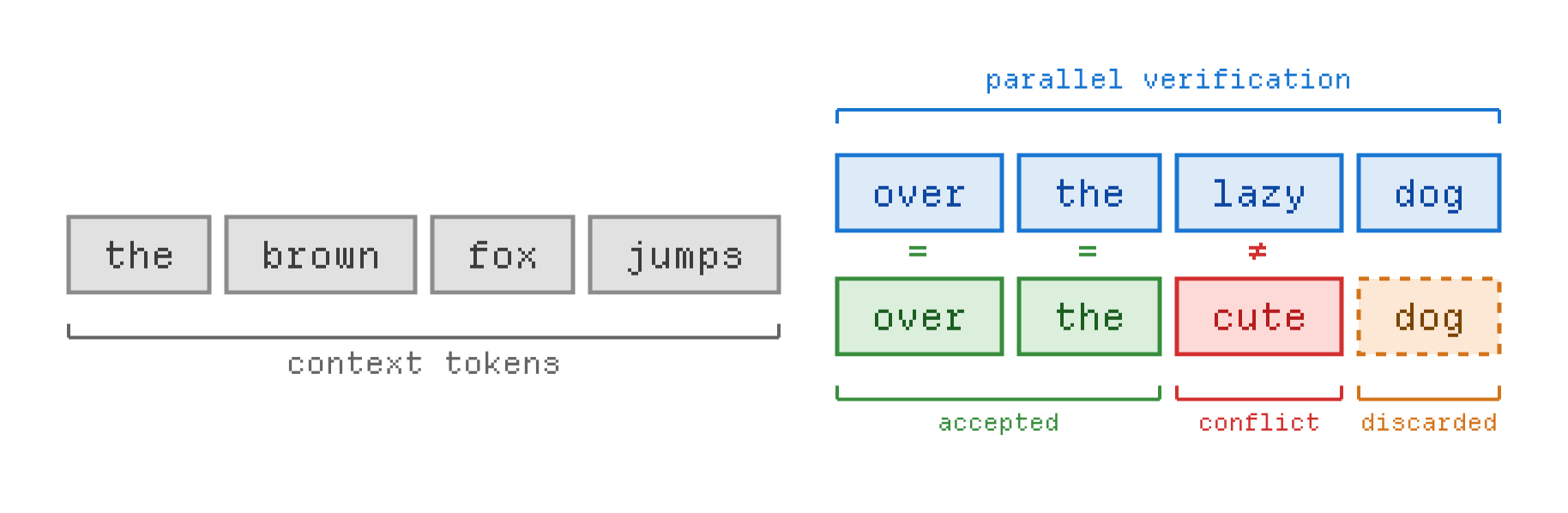
At each step, when processing a sequence x of length t, a speculative decoding algorithm (usually, a small neural network) makes a guess about the value of n future tokens, denoted draft (where n is usually small, between 2 and 8).

Next, the model is run on the concatenated sequence x + draft. The model’s output probabilities let us know whether the draft is correct, partially correct or incorrect.